


Aujourd’hui, la plupart des gros registres de noms de domaine reçoivent les demandes de création et modification de ces noms via le protocole EPP (Extensible Provisioning Protocol). Le Bureau d’Enregistrement parle avec le registre en utilisant ce protocole. Mais un projet existe pour remplacer EPP par RPP (RESTful Provisioning Protocol). Ce projet en étant au tout début, il est encore temps de faire connaitre votre avis.
Les limites d’EPP
Le protocole d’avitaillement EPP (Extensible Provisioning Protocol) marche bien et est aujourd’hui très largement utilisé par de nombreux registres de noms de domaine1. Ceux qui sont sous contrat avec l’ICANN ont d’ailleurs l’obligation de fournir une interface EPP. EPP a été normalisé par l’IETF (Internet Engineering Task Force) en 2004 et la norme actuelle est composée de plusieurs documents, le principal étant le RFC 5730. Plus de vingt ans après sa normalisation, souhaite-t-on continuer avec EPP ?
Petit point au passage. Dans le monde des services accessibles via l’Internet à des programmes, on parle souvent d’API (Application Programming Interface). Dans le contexte de cet article, il n’y pas vraiment de différence entre un protocole et une API, mais dans un contexte plus général, API est en général utilisé pour un type restreint de protocole2. Notez que les BE (Bureaux d’Enregistrement) ont accès à une API pour les opérations à l’Afnic.
-
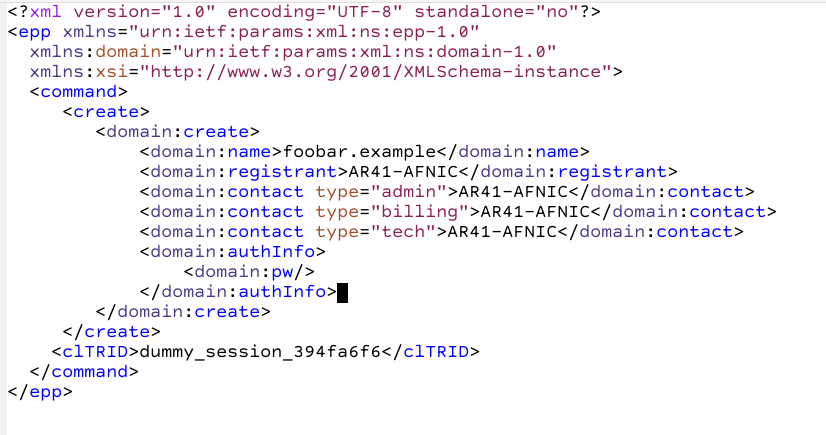
Les données envoyées par un Bureau d’Enregistrement pour créer un nom de domaine sont représentées en XML (Extensible Markup Language). Sur cet exemple en XML, la requête EPP crée le nom de domaine foobar.example, en indiquant son titulaire et les contacts du domaine.
-
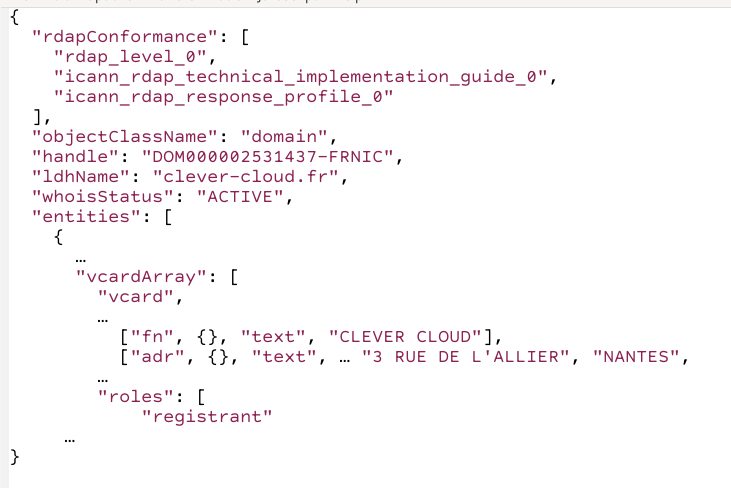
Les données envoyées par le serveur RDAP du registre sont représentés en JSON (JavaScript Object Notation). Sur cet exemple du serveur RDAP public de l’Afnic, le serveur RDAP, répondant à une demande d’information sur le domaine clever-cloud.fr, indique notamment que le titulaire est la société Clever Cloud, à Nantes.
Certaines personnes ont identifié des limites d’EPP. (Mais tout le monde n’est pas forcément d’accord avec cette perception.) Les reproches portent sur le fait qu’EPP utilise XML (Extensible Markup Language), norme du W3C (World-Wide Web Consortium) que certains trouvent complexe. D’autres reproches concernent le fait qu’EPP repose directement sur une connexion TCP (Transmission Control Protocol), ce qui rend difficile son déploiement dans des environnements où tout est censé fonctionner sur HTTP (Hypertext Transfer Protocol)3. Entre autres points, cette utilisation de connexions TCP de longue durée (des jours, voire des semaines) peut rendre difficile certains services comme la répartition de charge. Enfin, il y a une question humaine : les développeurs et développeuses junior ne connaissent souvent que HTTP et le format JSON (JavaScript Object Notation). Ce dernier format est par exemple celui utilisé dans le protocole RDAP (Registration Data Access Protocol), qui permet d’accéder aux informations sociales sur un nom de domaine.
Les principes de RPP
C’est sur la base de ces constatations que l’idée s’est fait jour petit à petit de remplacer EPP par un autre protocole, baptisé RPP (RESTful Provisioning Protocol). À l’heure actuelle (décembre 2024), RPP a un nom mais le protocole n’existe pas encore. C’est juste une série de principes de base, qui attendent d’être incarnés dans un réel protocole. Vous ne verrez donc pas RPP tout de suite. Quels sont ces principes ?
- Architecture REST (REpresentational State Transfer). Cette architecture, qui est très largement adoptée aujourd’hui pour beaucoup d’API réseau, repose sur l’idée de nommer les ressources qu’on manipule dans l’URL (Uniform Resource Locator, l’adresse d’une ressource sur le web) et de différencier les actions par l’utilisation de méthodes HTTP différentes. Ainsi, on pourrait, par exemple, récupérer de l’information sur le nom de domaine example par une requête HTTP GET sur l’URL https://rpp.nic.example/domains/toto.example et supprimer un nom inutilisé par une requête HTTP DELETE sur ce même URL. D’autre part, lors de l’utilisation de REST, chaque requête est auto-suffisante, il n’y a plus de notion de session comme en EPP. Une autre des conséquences d’utiliser REST est que certaines opérations peuvent être faites depuis un navigateur web ordinaire.
- Utilisation exclusive de HTTPS (Hypertext Transfer Protocol Secure) comme protocole de transport4, comme pour RDAP.
- Réutilisation, autant que possible, des services existants pour HTTP comme l’authentification5 (au lieu de l’authentification spécifique qu’utilise EPP), la limitation de trafic ou la répartition de charge6,
- Utilisation du format JSON, norme IETF (RFC 8259) pour représenter les données envoyées au registre ou reçues de lui.
Le travail de l’IETF
On l’a dit, RPP n’existe pas encore, il s’agit d’une idée. Les promoteurs de cette idée avaient envisagé de faire développer le nouveau protocole par le groupe de travail Regext de l’IETF, groupe qui normalise EPP et RDAP. La charte de ce groupe ne prévoyant pas de travail sur d’autres protocoles, le chemin actuellement suivi est de créer un nouveau groupe de travail, qui sera nommé Rpp. Au 3 décembre 2024, le groupe n’est pas encore créé mais cela sera probablement fait bientôt, la réunion qui s’est tenue le 6 novembre à Dublin indiquait une nette volonté d’y arriver.
L’avenir de cette idée est incertain. Le groupe RegExt a déjà beaucoup de travail et ce sont souvent les mêmes personnes qui devront travailler sur RPP. De plus, normaliser est une chose, déployer en est une autre et, pour l’instant, il est difficile de dire si RPP suscitera l’adhésion. L’ICANN (Internet Corporation for Assigned Names and Numbers), par exemple, n’a pas encore pris position, ce qui est logique vu que RPP n’en est qu’au début.
Notons que bien des points techniques restent ouverts dans la définition de RPP. Ainsi, la répartition des informations entre les champs de l’en-tête HTTP et le corps des messages (en JSON) reste à voir. L’identificateur d’une commande (l’équivalent du clTRID d’EPP) sera-t-il le champ RPP-clTRID: ou bien le membre clTRID d’un objet JSON ? Cela présente un avantage : le protocole n’étant pas terminé, vous pouvez intervenir dans le projet et faire connaitre votre opinion.
Mise en œuvre
Pour programmer un client RPP, lorsque le protocole sera défini, il ne devrait pas y avoir trop de difficultés. Tous les langages de programmation disposent de bibliothèques logicielles permettant de faire facilement des requêtes REST (bibliothèque HTTP, bibliothèque JSON…). Dans certains cas, on peut même utiliser un navigateur web ordinaire. Et il existe aussi des programmes tout faits comme, en ligne de commande, curl.
Pour programmer le serveur (mais seul le registre aura à le faire), il existe de même d’innombrables cadriciels pour réaliser un serveur REST et la programmeuse ou le programmeur RPP aura de nombreux outils à sa disposition. Un des buts du projet RPP était justement de permettre l’utilisation des nombreux logiciels déjà écrits qui facilite la réalisation de clients et de serveurs REST. Cela inclut aussi des outils de test et de documentation comme ceux existant autour d’OpenAPI ou TypeSpec.
Une fois le serveur programmé, il reste à l’héberger. RPP est prévu pour pouvoir être hébergé dans les environnements dits serverless7, qu’ils soient sur l’infrastructure du registre (par exemple en utilisant des logiciels comme OpenFAAS, Fission ou Knative), ou bien chez des hébergeurs spécialisés comme Heroku, Vercel ou Clever Cloud, qui dispensent complètement développeuses et développeurs de l’administration système.
Un exemple
Le service en question est un simple démonstrateur, il ne prétend pas être un vrai système de gestion de registre et il n’est pas une vraie mise en œuvre de RPP, ne serait-ce que parce que le protocole n’est pas encore défini. Dans les exemples suivants, on crée, on obtient de l’information sur et on détruit un nom en utilisant curl :
% curl --request PUT --data '{"holder": "Jean Durand"}8' \
https://registry.courbu.re/domains/foobar.example
{"result": "foobar.example created", "status_code": 2019, "status_message": "Created"}
% curl https://registry.courbu.re/domains/foobar.example10
{"result": "Domain foobar.example exists", "holder": "Jean Durand", "created": "2024-12-02T18:56:48.042794", "status_code": 200, "status_message": "OK"}
% curl --request DELETE https://registry.courbu.re/domains/foobar.example
{"result": "foobar.example deleted", "status_code": 202, "status_message": "Accepted"}
% curl https://registry.courbu.re/domains/foobar.example
{"result": "Domain foobar.example NOT found", "status_code": 404, "status_message": "Not found"}
-
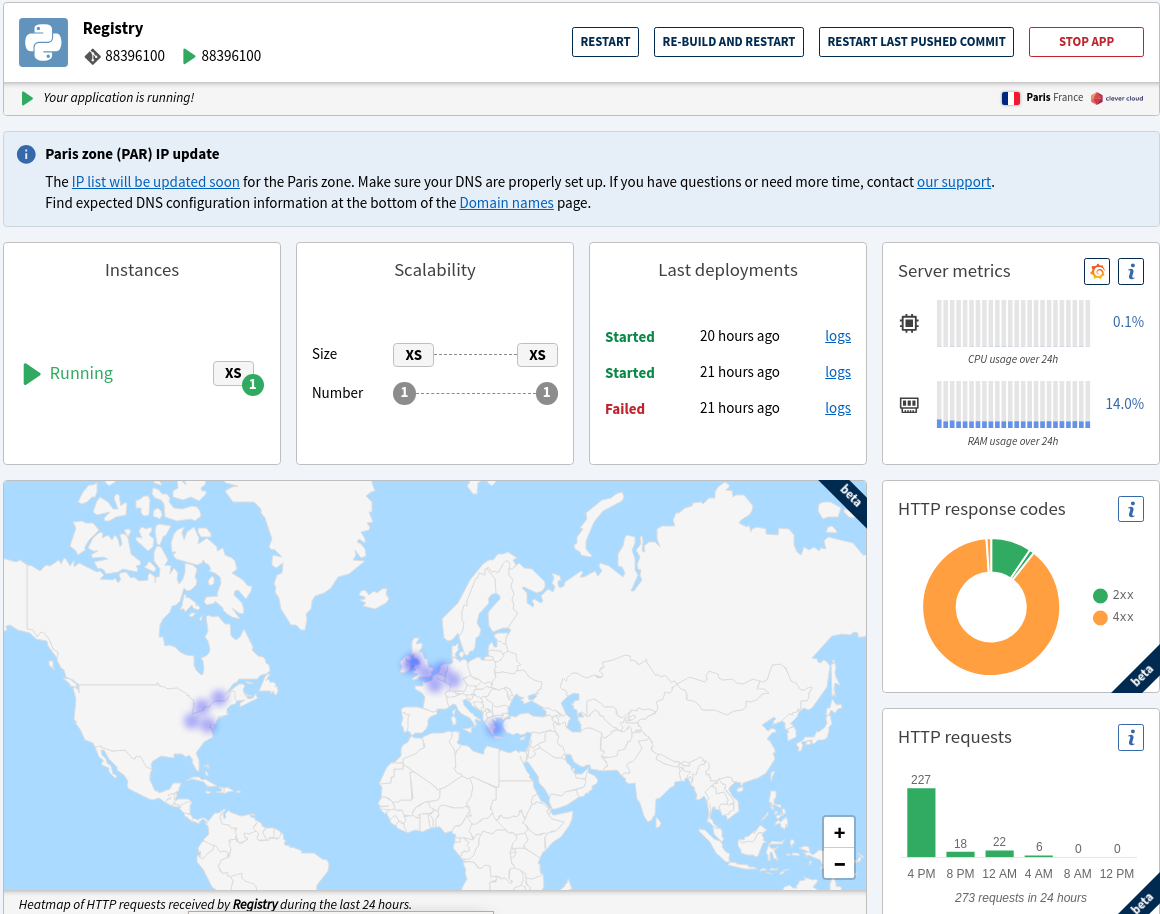
Le tableau de bord Web que l’hébergeur (Clever Cloud) présente au développeur responsable d’une application. On y voit l’identificateur de la version de l’application qui tourne en ce moment, les codes de retour HTTP sous forme d’un diagramme, le nombre de requêtes HTTP faites à l’application, une carte mondiale indiquant l’emplacement des requêtes HTTP reçues lors des dernières 24 heures.
Le service est hébergé chez Clever Cloud et consiste en un programme en Python de 140 lignes et une base de données PostgreSQL. Naturellement, un vrai serveur RPP serait bien plus complexe et riche.
Conclusion
Le travail sur RPP a à peine commencé donc n’hésitez pas à faire entendre votre voix, notamment si vous être l’employé d’un registre ou d’un BE. L’API de l’Afnic pour ses BE a souvent été citée lors des discussions donc il est possible que le futur RPP y ressemble.
1 – D’autres registres, comme ceux d’adresses IP tel que le RIPE-NCC en Europe, n’utilisent pas EPP.
2 – Le terme d’API désigne historiquement l’interface d’une bibliothèque logicielle locale, que des programmeuses et programmeurs utilisent pour enrichir le logiciel qu’elles ou ils développent. Aujourd’hui, il désigne souvent également un ensemble de fonctions qu’on peut appeler à travers le réseau. Le passage d’un sens à l’autre a, entre autres, des conséquences sur les questions de licence logicielle, une licence comme l’Affero a été spécialement conçue pour le cas de programmes auxquels on accède via le réseau.
3 – Par exemple parce qu’un pare-feu ne laisse passer que ce protocole, ou bien parce que l’on souhaite utiliser un hébergement dit serverless, qui ne repose en général que sur HTTP.
4 – Il y a aussi un travail en cours sur un protocole EoH (EPP over HTTPS) qui est très différent de RPP. Il ne suit pas les principes REST et les requêtes ne sont pas auto-suffisantes. Pour EoH, HTTP est juste un protocole de transport.
5 – Domaine pour lequel HTTP dispose de nombreux mécanismes, voir par exemple les signatures HTTP du RFC 9421.
6 – Le RFC 9205 détaille les précautions à prendre pour bâtir un protocole au-dessus de HTTP, ce qui sera le cas de RPP.
7 – Terme qui est évidemment marketing, comme « cloud », « intuitif » ou « intelligence artificielle ». Il y a bien un serveur, mais le développeur n’en est pas conscient et ne connait pas les gens qui le gèrent. Notons également que je ne vais pas rentrer dans le débat sur « qu’est-ce qui est du vrai serverless » puisqu’il en existe plusieurs définitions possibles.
8 – Les données sur le titulaire, encodées en JSON, seront transmises au serveur. Les autres requêtes ne nécessitent pas de données.
9 – Si on veut voir le code de retour HTTP, on peut aussi lancer curl avec l’option --write-out "\n%{http_code}\n » ou bien simplement en mode bavard (verbose).
10 – Cette commande aurait également pu être faite avec un navigateur web ordinaire, puisque on utilise la méthode standard des navigateurs, GET.
Sur le même sujet
Nouvelle norme TCP, le RFC 9293
Une norme technique nommée « RFC 9293 » a été publiée ...
05/11/20
Evolutions du DNS et ses protocoles : l’Afnic publie un ensemble de ressources sur DoT et DoH
Pour faire suite au wébinaire « Comment créer et tester votre résolveur DNS sur TLS et DNS sur H...
Que se passe-t-il à l'enregistrement d'un domaine?
Cet article vous présente les différentes étapes de l'enregistrement d'un nom de domaine....
À la une

27/03/25
L’Afnic, association en charge des noms de domaine en .fr, ...
En savoir plus
Un ensemble de traités internationaux, regroupés sous le ...
En savoir plus